

Today AI seems to be everywhere and is trying to automate almost everything we use or interact with daily. But somehow the large-scale industrial systems seem to adapt to the application of AI slower than expected. When we talk to the practitioners and managers, they say that their “systems are complex”, “existing processes are just fine”, “AI is not dependable enough”, “not enough AI skills”, and “don’t know where to start” and “how to provide enough data for AI implementation”. The last one is particularly important. But as we see it, the core problem is to start from scratch for each implementation. The only area where industrial systems made some progress is related to images where transferring knowledge from a pre-trained knowledge base is prevalent and produces good results. Growth is not possible if each machine needs to be treated according to the first principle of AI. Like engineering practices itself, AI in Industrial systems has to build onto each successful implementation such that limited machine-specific data can make each machine intelligent. That is why the evolutionary learning processes are so important and need to be studied further for engineering systems.
What is the problem of getting data :
Most of the industrial systems are dynamic. So the data produced by them depend on the system’s dynamics. They also change their characteristics with time. Often most of the important I/O data required may not be measured in an industrial system. So getting comprehensive data to make a system intelligent, self-correcting and self-recovering will remain a challenge for every system. Another important issue is to get data on the failures or in more technical terms for anomalous situations. Machines are designed to avoid failures and therefore getting the data for failure conditions is very difficult. Sometimes bespoke experiments need to be developed to get training data for failures and other anomalous situations. This is required for effective and evolutionary AI implementations for industrial systems.
What are those learning processes that leverage similar data :
When comprehensive data is not available for a robust model, various types of learning can be used that leverage similar data. One such learning process to overcome the data problem is transfer learning for the machines.
Transfer Learning:
The field of transfer learning examines and develops machine learning methods using knowledge acquired from previously solved source tasks to more efficiently solve new target tasks. To give an example, let’s assume that there is a model of a 6-jointed serial robot. Using transfer learning, that model can be leveraged for training another similar robot of different dimensions or different numbers of joints
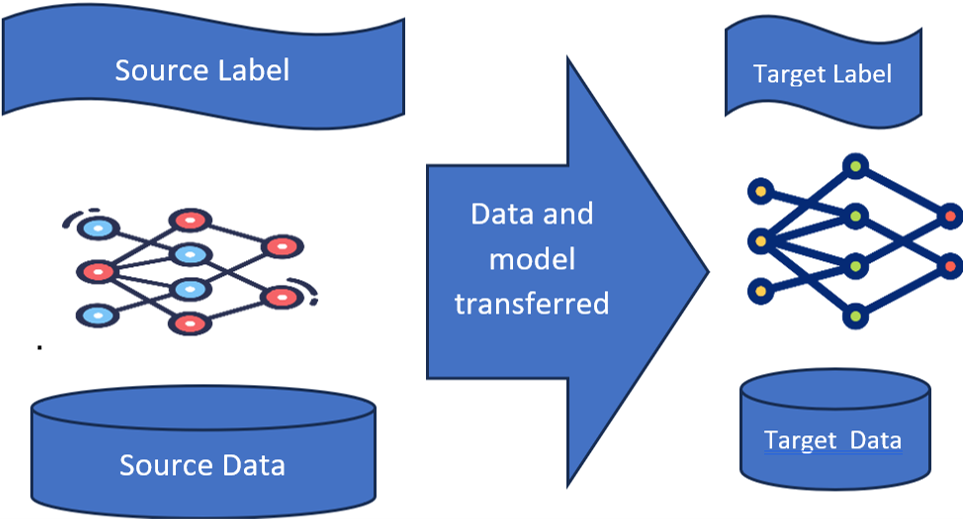
Fig 1: Limited data and labels of the target (T.) system leverages transfer learning
Different names are given to transfer learning process depending on the types of knowledge/data/part of the model is transferred to the target system. Names such as Instance transfer, feature transfer, knowledge transfer and parameter transfers are used. In simple language, similarities between two machines are identified and lesser data is used to reach the target model starting with those identified similarities.
Continuous Learning:
In continuous learning, the problem of the lack of data is handled by the continuous training process thereby increasing the accuracy and efficiency of the task being performed. This type of learning can be used for learning one task, learning multiple tasks or learning a new domain with multiple tasks. The training strategy and learning strategy change based on the learning goals.
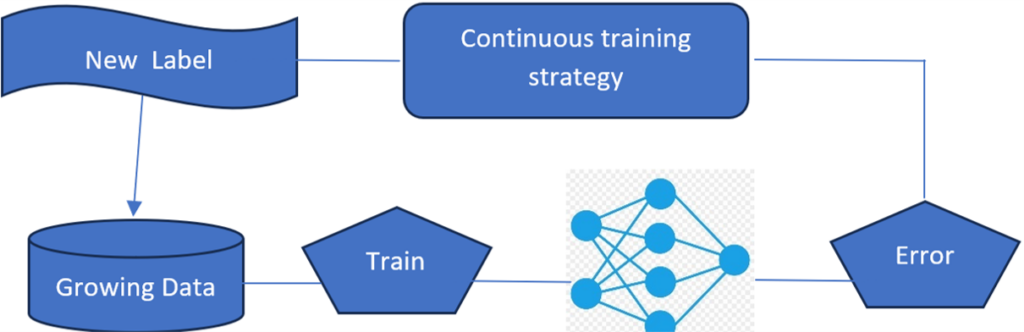
Fig 2 : Continuous learning strategy of the ML/DL model of the machine
adaption of the driving parameters in autonomous driving, and learning of the optimized parameters for changing dynamics because of wear and tear are very good examples of continuous learning.
Federated Learning
Federated learning is a type of machine learning where multiple devices or systems collaboratively train a model while keeping the data localized. Instead of sending all the data to a central server, each device (or node) trains the model using its own data and then shares only the learned model updates (like gradients) with a central server. The central server aggregates these updates to improve the global model.
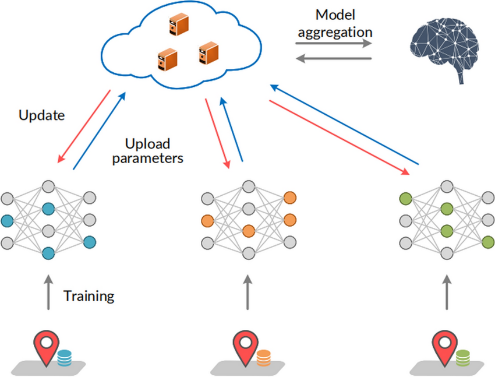
Fig 3: Federated learning scheme for the industrial systems
Many of the industrial systems are collaborative and hierarchical. When a new system is introduced or the configuration of the system changes it is better to look at federated learning and systems to solve the problem. In an environment where multiple systems components are supplied by various OEMs, the collaborative approach of Federated learning is extremely important.
Our View
In the current state of AI in industrial systems, one needs to implement various strategies that involve multiple learning techniques. Application and adaptation of these learning techniques not only need algorithmic knowledge of ML/DL/GEN AI but also deep knowledge of the system on which algorithms are applied. Various techniques of transfer learning and strategies of continuous learning need knowledge of how the source system relates to the target system or whether a part of the system knowledge can be applied to another part of the target and how the relation needs to be built. Effort has to be made to make this process more intuitive and mechanical. Industrial GPT or a large-scale pre-trained transformer-like system for industry is very much a movement in that direction but till they are robust and formalized, implementers need to directly impart the basics of engineering very perfectly in the AI models of engineering.